
An AI second brain is a structured, written knowledge system that your AI tools read from before they do any work, so they start every task already knowing your standards, your clients, and the mistakes you have already made. We built one at May Media, and it quietly became the most important thing we own. This is the personal version of how it happened, why it works, and what it now runs for us every single day.
I want to be clear about where this came from, because I did not invent any of it. I came across two concepts online (more on this later), fed them to my Claude Code agent. Then I talked through what would actually fit a small marketing agency with my agent and then we built our own version together. The result is the reason our output keeps getting better instead of starting from zero every time.
It starts with a framework called WAT
Before I explain the knowledge system, you need to know the foundation that it is built on. Everything we run sits on a simple architecture called WAT: Workflows, Agents, and Tools. The whole idea is to let the AI do the thinking and let plain code do the doing.

Why we never let the AI do everything
This part matters more than it looks. If you let an AI handle every step of a task directly, small errors stack up fast. Say the AI is right 90 percent of the time on any single step. That sounds great until you chain five steps together. Then your odds of the whole task being correct are 0.9 to the fifth power, which is about 59 percent. You would fail four out of every ten runs.
Accuracy compounds against you. Move execution to code and it stops.
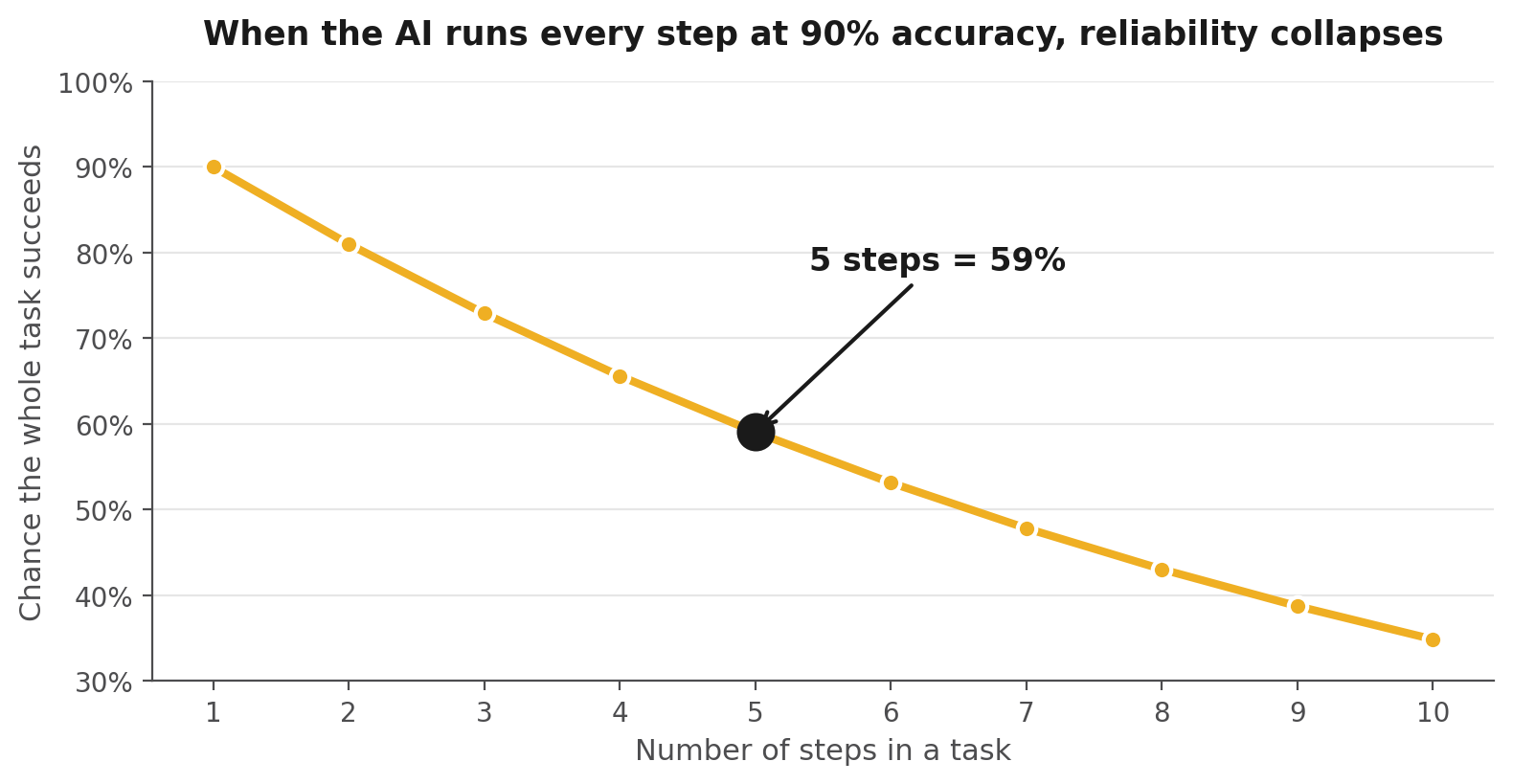
So we move execution out of the AI and into code. The AI reasons, decides, and coordinates, which is the work it does best. The code runs the steps, which is what code is good at. Reasoning stays smart, execution stays reliable, and the task survives and succeeds.
The second foundation: claude.md and agents.md
There is one more piece you need before the knowledge system clicks. AI coding agents look for a special instructions file the moment they open a project. It tells them how you work before they touch anything. There are two names for it, one is clearly only for Claude, the other is for any other coding agent (Codex for example):
- claude.md is read by Claude Code specifically. It is the house rules for our agent.
- agents.md is the open standard that every other coding agent reads. Same idea, but it is the shared file the rest of the ecosystem agreed on, so your instructions are not locked to one tool.
We keep both, because the instructions should not depend on which AI happens to open the project. You can even just keep an agents.md file and in your claude.md just point to the agents.md so you don’t have to write both. You would only need both if you have both Claude Code and another coding agent. A trimmed version of ours looks something like this:
# Agent InstructionsYou are working inside the WAT framework (Workflows, Agents, Tools).1. Read the relevant workflow before producing anything.2. Look for an existing tool before building a new one.3. When something breaks: fix the tool, verify, write down what you learned.4. Durable knowledge goes in the wiki. Task state goes in the database.5. Never claim a task is done until you have checked the live result.
That file is the handshake. It points the agent at the knowledge system instead of letting it guess.
Where the idea came from
I got the second-brain idea from two places, and I want to credit both because they did the hard thinking.
The first was Andrej Karpathy, one of the most respected people in AI. He was a co-founder at OpenAI (Chat GPT) and now works for Anthropic (Claude). In a post back in March titled LLM Knowledge Bases, he described keeping his research as a wiki of plain markdown files that the AI itself builds and maintains. He drops raw sources into a folder, the AI writes summaries, sorts them into concepts, and links everything together, and he barely edits it by hand. The part that stuck with me was his point that you do not need fancy retrieval tricks for this. At a human scale, the AI can simply read a well-organized wiki and answer hard questions against it. You can read Andrej Karpathy’s knowledge system post for the original framing.
The second was Nate Herk, whose videos turned the idea into something I could actually build. Two of them are the backbone of what we run. His agentic workflows video and his Claude Code walkthrough are where I learned about the WAT framework and the claude.md file for the first time. Then his knowledge system walkthrough where he discussed Andrej Karpathy’s memory system and broke down how to build it
Now I did not just copy a template. First, I pulled the transcripts from those videos and Karpathy’s post and fed them into Claude Code, and then we talked through what would actually fit our marketing agency and how to implement our workflows and be able to increase our productivity on tasks. I kept the WAT framework and the claude.md methods close to how Nate teaches them, then adjusted the instructions file to our own standards so it fit our company. We kept the heart of Karpathy’s idea, a written knowledge base the AI reads. And then we took our own turn on the memory side, splitting durable knowledge from task history, which is where most of our improvement came from.
The two-part memory: a wiki and a database
The most useful decision we made was splitting memory into two kinds, because they answer two different questions.
Part one: the wiki, for things that are true
The wiki is our durable knowledge. It is a folder of plain markdown files, each one a single page, cross-linked the way a personal wiki or a tool like Obsidian works. Rules for writing, how our tools and workflows work, the quirks of every platform we touch, the facts about each client. Every page carries a small header of metadata and an index page sits on top so the AI can find the right page fast instead of reading everything.
—title: Blog Writing Rulestype: ruletags: [blog, content, linking]related: [“[[wordpress]]”, “[[seo-anchor-text]]”]—# Blog Writing RulesCanonical rules for producing blog posts across every client…
The double-bracket links connect related pages, so the knowledge behaves like a graph instead of a pile of documents. When the AI needs to know how to use a tool, it follows the link rather than guessing.
Part two: the database, for things that happened
This is where we went our own way from Karpathy’s setup. Alongside the wiki we keep a database that records task state and execution history: what we worked on, what finished, what is still pending, what errored and why. The wiki holds what is true. The database holds what happened. Keeping them separate is what lets a brand-new session pick up an unfinished project exactly where the last one stopped.

On the storage software itself I will stay vague on purpose. We use a standard hosted database for the task-state side. The specific product does not matter to the idea just the database function you could use Supabase, Neon, Convex, or just have it tracked in a google sheet even, just make sure the sheet is secure.
The payoff: it never loses its place, and it learns from its mistakes
Two things fall out of this design, and they are the reason I am glad that I am glad I built the system.
It always picks the project back up
Because every task writes its state to the database, I can close everything, walk away, and open a fresh session days later. The AI reads what is pending, sees where we stopped, then continues. There is no long re-briefing, no hunting for where a file ended up. The work has a memory that outlives any single conversation/session.
It gets better every time it fails
This is the part that compounds. We run a simple loop on every failure:

Without that loop, every future session would rediscover the same problem and pay the same cost. With it, each mistake is solved once and then it is institutional knowledge. Our reliability climbs instead of resetting every time we open the program, which means each output is a little better than the last.
This works not just for failures, but revisions given as well. Any time I give detailed revisions on an output whether that be a content plan or blog post. It saves those preferences and if they are key elements to a brands voice it then also saves those as a brand rule.
What the second brain let us build
A knowledge system is only worth it if it produces something. If you don’t produce anything then you wasted your time building a system that does nothing. What I mean by this is that you cannot get your system to be efficient without training it, and you can’t train it if you don’t go through any tasks. Building a system that creates an output you actually can use will do way more for your ai agent than sitting there making sure you install every cool MCP you find.
Here are three of the systems it made possible, if you would like to discuss these in more detail check out our May Media Stars membership or schedule a discovery call, I would love to talk to you.
A content planning pipeline
This one researches what a client’s audience is searching for and engaging with, checks which of those questions are showing up in AI-generated search answers, studies what is currently being cited. It then compares these findings with search volume research, competitor research, social media trend research, and sales and engagement trends on certain services/products. It turns all of it into a quarter of blog topic outlines, which is stopped by a human approval gate. Once I review the topics and give changes or approve them, my agent then drafts the blogs, a quarterly social media plan, and video content plans. The clients or I both revise the blogs and I revise the plans before they get sent to the relevant teams. I make sure to tell the agent the revisions (or have it analyze the changes if I do them myself) so that it learns for the next time around.
Two human approval gates sit in the middle, one for strategy and one for final voice, so a person always makes the calls that matter. The knowledge system is what lets it produce work that already sounds like us and already follows our rules, because those rules live in the wiki and load automatically. Nothing will be perfect so always make sure to revise and over time the output gets better and better.
An SEO and schema audit system
This workflow reviews a website’s technical SEO and its structured data (the behind-the-scenes markup that tells Google what each page is). It checks Semrush, Google Search Console and Google Analytics, finds what is broken or missing, fixes what can be fixed safely through the site’s own tools, and then verifies the live result rather than trusting that the change worked. Then if there are fixes that need manual attention it generates me a report with the items listed in order of importance. Every quirk it has ever run into on a platform is written down, so it does not relearn the same lesson on the next site and can identify and fix it easier the next time it comes across it.
News agents that write in each client’s voice
These watch trusted news sources for a client, confirm a story across several independent outlets before trusting it, draft an article in that client’s voice and discusses the relevancy to their audience, and run it through a separate AI for quality and fact-checking (more on that later). The blogs are then held for human approval before anything publishes. An example is ours polls for Google or AI news and then explains why it matters to small businesses, to help them compete with corporations. The knowledge system allows a new agent to know our content rules and a client’s brand voice simply by linking pages that already existed.
That last point is the quiet superpower. Once the knowledge exists in one place, every new system you build gets to stand on it instead of starting over.
How this compares to Google’s Open Knowledge Format
After we had been running this for a little bit, Google published something called the Open Knowledge Format, or OKF. It is a standard shape for exactly this kind of AI-readable knowledge: markdown files, metadata headers, typed pages, an index, and links between ideas. When I read it, my first reaction was that it described what we had already built and that Karpathy had gone viral for months prior. That was a good feeling, because it meant we weren’t behind the technology and instead are on the right path for creating better systems.
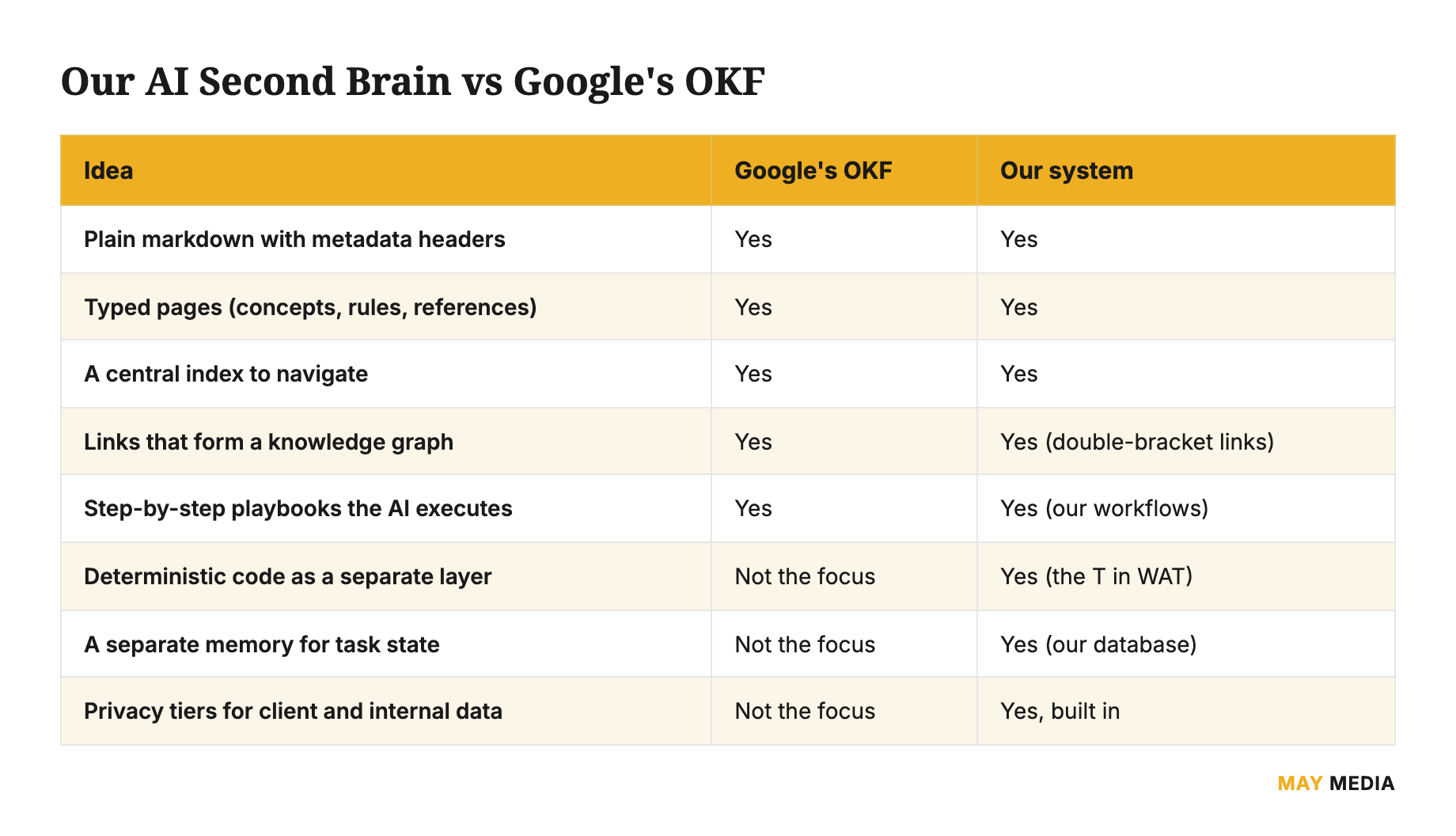
Where we go further is the parts a standard ruleset does not need to solve. OKF is about the knowledge files. Our system adds the execution layer that runs the work, the separate memory that tracks what happened, and the privacy tiers that keep client information walled off from anything public.
One AI checks another’s work
There is one more habit that lowered our error rate more than anything else, and it has nothing to do with making a single model smarter. We have a second AI audit the first one’s work. Every time Claude Code finishes a commit, we run it through Codex, a different model, to review the changes and hunt for errors before they ship.
Think about why a writer has an editor. The person who wrote the story is too close to it. They read what they meant to say, not what is actually on the page, so they miss the typo, the broken logic, the claim that does not hold up. A fresh set of eyes catches it in seconds. The same is true for AI. A model reviewing its own output tends to agree with itself. A different model, with no attachment to the work, sees the mistakes the first one glossed over.
Letting one model audit another has caught far more than having a model check itself ever did. It is the difference between proofreading your own email and handing it to a colleague first. We build that second opinion into the process, so errors get caught by a fresh set of eyes, not by the same eyes that made them.
Two ways to go from here
If there is one thing I would hand you from all of this, it is the core move: write your knowledge down in plain text, in a way your AI can read such as a markdown file or a word document, and split what is true (your systems, tools, skills, and workflows) from what happened (task statuses, history, and how to fix issues). That alone will change how much you can trust an AI agent with your real work.
If you want to learn how to build systems like this yourself, that is exactly the type of thing I will be teaching in our May Media Stars membership, along with other marketing lessons, and how to automate various systems. We are trying to build a community of small business owners to help teach them things to get ahead and for engagement between so we can learn from each other as well.
If you would rather have a system built specifically for your business, book a discovery call so we can do an automation audit to help you increase productivity and lessen tedious burdens.
The most expensive system is the one you build blindly.
Start with established knowledge, and growth follows.
Jordan May
Director of SEO and AI Systems

The full breakdown in a 12-slide PDF you can keep, skim, or share with your team.
Download the PDF